Introduction
Language models are trained on vast amounts of data. But what happens when someone wants their information erased from this artificial memory? Consider this: An author discovers their work was unknowingly used to train a language model. A social media user wants their personal data scrubbed from AI systems. These aren't just "what-if" scenarios - they're the basis for real-world lawsuits (Tremblay v. OpenAI, Inc, Kadrey v. Meta Platforms, Inc., Chabon v. OpenAI, Inc., DOE 1 v. GitHub, Inc.) and regulations like the GDPR.

The challenge? Surgically removing specific data from a language model's "mind" isn't as straightforward as hitting the delete key. Exact unlearning would require retraining the entire model without the to-be-removed data (often referred to as the "forget set"), which is impractical for modern-day AI systems.
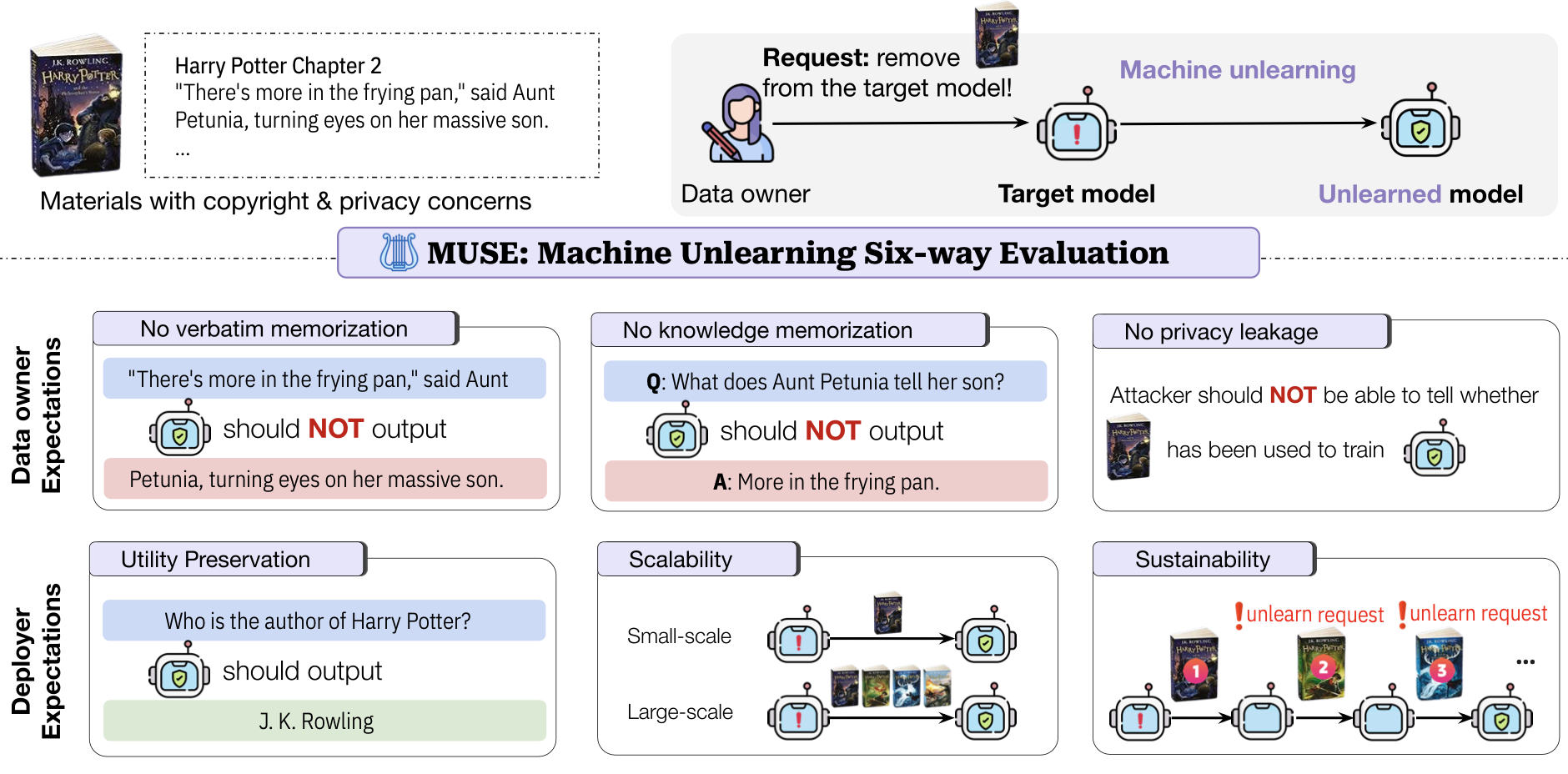
This dilemma has sparked a race to develop "approximate unlearning algorithms" - but how can we verify their effectiveness? To address this critical question, we propose Machine Unlearning Six-Way Evaluation (MUSE): a benchmark designed to evaluate six key properties of unlearning algorithms.
- MUSE considers both the data owner's privacy/copyright concerns and the model deployer's practical needs.
- MUSE is designed to reflect real-world settings by incorporating large-scale corpora (6.5M tokens) with critical materials such as book corpora and news articles.
- We used MUSE to evaluate eight representative machine unlearning algorithms, revealing that they generally struggle to balance data owner expectations with model deployer considerations.